

Top 10 in Demand Data Science Technologies
Top 10 in Demand Data Science Technologies
Data science technology is an interdisciplinary field of data analysis that deals with protocols, algorithms and systems that are utilized to extract information and insight from large amounts of data. The extracted data can be structured and un-structured. Since data science implements theoretical knowledge from various fields of science such as computer science, mathematics and information technology; it has greatly increased its value and applications in business and healthcare organizations.
Some of the dominant data science programming languages and tools as per their characteristics are:
- Python: Very useful for general programming
- Pandas: Widely being used for data manipulation
- Tableau: Applicable for data visualization
- TensorFlow: The most popular artificial Intelligence library.
It is recommended for aspiring data scientists to focus at one of the programmes at a time. It ensures a much better understanding of the technology with complete command.
Data science has come a long way in getting incorporated with the operational mechanisms of many major industries. In the past decade, it has become an integral part of the global economy and business manoeuvre. It ensures better brand establishment through strong engagement and relationship between businesses and clients.
Hereby mentioning top 10 in demand data science technologies that have been featured in the Forbes list for serving as the essential core of the data science field:
Predictive analytics
NoSQL databases
Search and knowledge discovery
Stream analytics
In-memory data fabric
Distributed data stores
Data virtualization
Data integration
Data preparation (automation)
Data quality
.
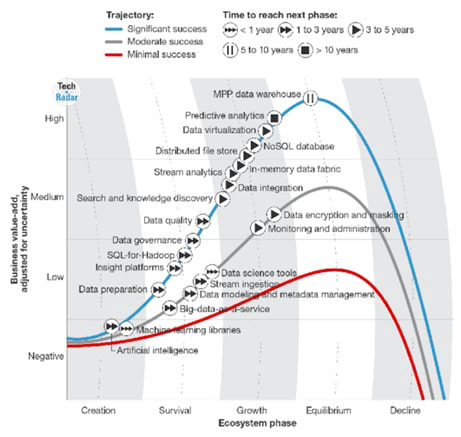
*Chart presented by Forrester Research
Top 10 in demand data science technologies
Predictive analytics
Predictive analysis is the process by which data analytics is used to make a predictive model based on data . Data analytics includes techniques such as data analysis, statistics, and machine learning techniques.
Predictive analytics operates with the aim of using data to reduce wastage, save time and cost reduction. The process employs variegated and big data sets into models that can produce precise and clear results for complete goal achievement.
Predictive analytics is used extensively in various industries such as healthcare, medical, pharmaceuticals, finance, agriculture, automotive, aerospace, construction, communication, etc.
NoSQL databases
The relational databases acquired by Structured Query Language is called SQL. SQL can be utilized to interact with relational databases that are stored in the data of columns and rows of a table. Whereas NoSQL or non SQL databases can store data in other formats as well that does not have to be in the form of relational tables.
There are different types of NoSQL databases that are characterized by their data model, such as key-value databases, document databases, graph databases and wide-column stores. These data models easily process massive data and facilitate scalable and manageable data load by assembling related data in a singular data structure.
Search and knowledge discovery
Also known as KDD or Search and Knowledge discovery, it refers to the widely used technique of data mining where a useful knowledge is discovered from a given mass of data.
The process of Knowledge Discovery in Database includes multidisciplinary activities such as, data access, data preparation, data selection, data storage, data cleansing, scaling algorithms to massive data sets, prior knowledge incorporation on data sets and solution interpretation from the observed results with accuracy.
KDD has great applications in the field of marketing, telecommunication, manufacturing, construction and even auditing process of fraud detection.
Search and Knowledge Discovery is also backed by Artificial Intelligence. This is done by discovering applied laws from experiments and observations.
Stream analytics
Streaming Analytics by definition simply means the potential to uniformly analyse the statistical information while processing the stream of data. Streaming Analytics provides detailed information about a live streaming data through data visualization, management, monitoring and real-time analytics. This helps in providing an accurate insight of the user’s behaviour and thus ultimately strengthens the businesses by generating more innovative ideas and maintaining competitiveness.
In-memory data fabric
In-Memory Data Fabrics refers to the transformations undergone by in-memory computing technology. In-Memory Data Fabric categorizes in-memory computing cases into independent classes. It includes data grid, computer grid, service grid, in-memory database, streaming and Complex event Processing, in-memory file system, distributed file system and many other in-memory computing components.
Even though all of these components are well integrated with one another, each of them can act as an independent component. This is one of the many advantages of In-Memory Data Fabric technology.
Distributed data stores
Distributed data stores are non-relational databases that allow users to access the data over a replicated number of nodes. It is a computer network which stores information on more than one nodes, peer to peer network.
It is based on an error-detection technique such as, forward error correction, which is meant to correct and recover damaged files. The original files that have been lost can also be recovered through this technique, making it one of the most reliable data science technologies.
Distributed databases exhibit both limited and wide-scale database systems. Bigtable by Google, Dynamo by Amazon and Microsoft Azure storage are the respective examples of distributed data store system.
Data virtualization
Data virtualisation is a logical data management technique which facilitates an application to utilize and manipulate the unified data without any prior knowledge about its technical details. It integrates different contrasting data of the systems and manages them for the governing bodies. Further the data is delivered to users all at the same time.
The retrieval of the data does not require fundamental details such as its source, format used and physical location of the data. However data virtualisation is capable to produce a single view of the complete data.
It does not follow the traditional process of data extraction, transformation and loading. Instead, it gets access to the source system for the data in real time. This characteristic makes data virtualisation almost error free. It makes use of a heterogeneous database system which do not utilize a single data model and reduces the load occupied by unused data.
This data science technology also take care of transcription of transaction data updates back to their source systems. It has wide industrial applications in data services such as data analysis of business information, business data integration and processes, Service Oriented Architecture (SOA), business intelligence services, master data management, tracking, retrieval and storage of digital information, cloud computing services , reference and analytical data management and Enterprise search system.
Data integration
Data integration is a data science technique which deals with the retrieval and arrangement of heterogeneous data in an integrated manner. It mainly combines technical data in the form of data sets, tables and documents from external divergent sources related to business processes and turn them into relevant and consequential information. Such information is applicable for users and various business organization departments to be merged for individual and business purposes. Most common example of data integration is Google spreadsheet integration. Another example is making a final report of a user’s data from sales and marketing operations.
Data integration is administered in an enterprise data warehouses (EDW) via large data resources. It accomplishes the objective of large scale data integration by extracting data from remote sources, aligning, merging and arranging the analytical data sets into a unified form. It aims at delivering useful and reliable data retrieved from multiple sources to establish a competent data pipeline and reducing the cycle time of data analytics.
Data automation
Data preparation or Data automation refers to the analysis of a data which follows the process of collecting, amalgamating, structuring and arranging. Data preparation is done for the purpose of data analysis, data visualisation and automation applications, which usually involves extracting data from different internal and external sources.
Data automation comprises of various components that exhibits following features. Such as:
Accessing, searching, pre-processing, profiling, sampling, cleansing, metadata and cataloging, data structuring, validation and transformation, modelling, discovering and suggesting properties, lineage and patterns, data curation, enrichment, data collaboration and profiling.
Data quality
Data quality is the process of planning, administration and management of quality of data by applying techniques which are authorised to be suitable for fulfilling the needs of data consumers.
It follows the process of Data profiling, Data standardization, Data monitoring and Data cleansing for affirming the quality of data.
Data quality (DQ) serves multifarious functions:
- It increases business values and organization’s data quality.
- It enhances efficiency and productivity of an organization.
- It abolishes any poor quality data and reduces risks of business loss.
- It secures and improves business reputation.
In conclusion, data science technology is the ultimate and dominant technology that is leading the modern world into a data science-driven future. For those who want to commence a successful career in data science, my suggestion is to go through and get well versed of all the technologies mentioned in this blog. Key to a prominent future in data science is to make a smart yet steady move. Get yourself well accustomed with each of them one by one. Try to focus on one then move on to the next.
.